Como Imprimir un Entero de 32 Bits en ASM
printf(«Imprimir en ASM no es tan facil como tu crees»);
El semestre en las universidades termina y con ello baja la cantidad de visitantes, dejando solo aquellos que vienen por gusto o porque realmente les interesa el ASM. Esta vez traigo un programita que convierte un valor binario de 32 bits en una cadena ASCII-Z.

Ya se lo que se han de estar preguntando los que no estan muy familiarizados con la programación en ensamblador: ¿Porque este desperdicia espacio en una tontería como esta? O peor aún ¿Y que este idiota no sabe que los números son diferentes a los “strings”?
Mientras mas avanzo en esto del Ensamblador mas me doy cuenta del daño que causa a a los programadores principiantes el empezar su aprendizaje con lenguajes de “alto nivel” (como me fastida ese término). Por todos es bien conocido el daño que hace iniciarse a programar con BASIC y todos sus descendientes y tal parece que cada nueva versión de BASIC tiene nuevas y mas novedosas maneras de echar a perder a los programadores mas jóvenes. No cabe duda de que el daño hecho por iniciarse en este tipo de lenguajes es muy dificil de remediar. Si me pusiera a enumerar todos necesitaría otras 3 entradas nada mas para el puro BASIC, pero en este caso creo que voy a blasfemar un poco.
Todos saben que como radical que soy, tengo muy poco respeto por la mayoría de los lenguajes autodenominados de “alto nivel”. Excepto por el viejo C que es el que mas se acerca al ASM. Sin embargo, para quienes se inician programando en C o alguno de sus derivados mas amistosos topan con piedra a la hora de comenzar a programar en ASM. Pues cosas que son relativamente sencillas en estos lenguajes son completamente diferentes, cuando no imposibles en ensamblador. Esta lista merece su entrada a parte pero el asunto a discutir ahora es la modesta función printf( );
printf(“La suma de %d + %d es igual a %d”,numero1, numero2, resultado);
Veamos los parámetros: el primero es una cadena de texto con signos de control que son remplazados por el contenido de las variables numéricas llamadas numero1, numero2 y resultado. Pero este proceso no es directo, primero la función debe de procesar por medio de un aceptor la secuencia de signos que se encuentran entre las comillas dobles e interpretar los signos de control como instrucciones. ¡En realidad esta sencilla cadena de caracteres puede considerarse un programa completo!. Y lo que dice es: Toma los 3 números cuyos valores te envío por el Stack, conviertelos en strings decimales e intégralos con el resto del string y luego le dices al sistema operativo que los despliegue. Eso sin mencionar la comprobación exhaustiva de tipos de las variables ni los formatos numéricos en los que debe de ser mostrado. De hecho, la leyenda de que una sola instrucción de C se convierte en cientas o miles de instrucciones en ASM es cierta sobre todo por instrucciones como printf(); y scanf();
Bueno, ahora que ya saben que un printf no es tan sencillo como parece vamos con el código:
;BIN2ASC.ASM
;Escrito por Mario Salazar el 11 de diciembre del 2009
;https://asm86.wordpress.com
;http://itzasm.ning.com
;Programita que despliega un numero de 32 bits en hexadecimal
;por medio de MessageBox. Para compilarlo con FASM solo presione
;la tecla F9. El numero solo puede ser cambiado en el codigo
;Lean el archivo bin2asc.xls para una referencia de las variables
format PE GUI
entry start
section '.code' code readable executable
start:
mov [eax_bin], 1234abcdh
;cambia el 1234abcdh por el numero que quieras entre 0 y 2^32
call bin2asc
;llamada a la funcion que convierte ese numero en cadena ascii-z
push 0
push debug_caption
push eax_ascii
push 0
call [MessageBoxA]
;mostrar una MessageBox que despliegue el numero
push 0
call [ExitProcess]
;terminar el programa
bin2asc:
pusha
;guardar los registros generales en el stack
xor eax, eax ;prepararse para el ciclo y
mov ecx, 8 ;cargar valor binario en edx
mov edx,[eax_bin]
lee_binario:
mov ebx, 0fh ;extraer los 4 bits mas bajos
and ebx, edx ;con una mascara de bits
mov al, [ebx + digitos]
push eax ;usar esos 4 bits como indice
shr edx, 4 ;a la tabla digitos
loop lee_binario ;por cada 8 numeros
;obtener 8 simbolos ascii y guardarlos en el stack
mov ecx, 8
mov edi, eax_ascii ;apuntar edi a la cadena ascii
escribe_binario:
pop eax
mov [edi], al
inc edi
loop escribe_binario
;sacar los simbolos ascii del stack y
;guardarlos en la cadena ascii
popa
ret
;restablecer los registros generales y terminar proceso
section '.data' data readable writeable
eax_bin dd 0 ;valor binario a convertir
debug_caption db 'Hex de 32 bits:',0 ;nombre de la ventana
eax_ascii db '00000000',0 ;cadena de salida
digitos db '0123456789ABCDEF' ;arreglo de simbolos hexadecimales
section '.idata' import data readable writeable
dd 0,0,0,RVA kernel_name,RVA kernel_table
dd 0,0,0,RVA user_name,RVA user_table
dd 0,0,0,0,0
kernel_table:
ExitProcess dd RVA _ExitProcess
dd 0
user_table:
MessageBoxA dd RVA _MessageBoxA
dd 0
kernel_name db 'KERNEL32.DLL',0
user_name db 'USER32.DLL',0
_ExitProcess dw 0
db 'ExitProcess',0
_MessageBoxA dw 0
db 'MessageBoxA',0
section '.reloc' fixups data readable discardable
En realidad la mayor parte del source pertenece al viejo PEDEMO.EXE del FASM. Pero no he “encapsulado” este “método” para que fuera mas sencillo de entender y a la vez mas dificil de lamear. Para compilarlo solo cárguen este programa en el IDE del FASMW y opriman F9. Pueden cambiar el número 1234abcdh por el que ustedes quieran ¡Incluso si lo dan en formato decimal o como una palabra de 4 letras!. Si hacen lo de las palabras con 4 letras (muchas de las cuales suelo gritarle a los lamers todo el tiempo) no olviden ponerla entre comillas dobles. No se asusten si de pronto alguna aparece al reves, se debe a algo llamado Little Endian que explicaré (de nuevo) otro día.
El programa tiene 3 elementos de datos:
eax_bin.- Es un espacio en memoria de 32 bits donde se va a guardar el dato a desplegar
eax_ascii.- Array de 9 bytes. Ocho son para los digitos y el ultimo en un cero binario que indica el fin de la cadena ASCII-Z
digitos.- Este es el mas importante. Es un array de bytes donde cada uno representa uno de los 16 digitos ascii que serán usados para formar la cadena de texto.
Ahora vamos con las instrucciones:
Antes y después de la función se guardan y restauran los valores de los registros generales con PUSHA Y POPA. Luego de guardarlos se escribe el entero de 32 bits en el registro EDX y en ECX se escribe un 8 en preparación para el ciclo de lectura que ha de repetirse 8 veces.
Hay un ciclo que lee el valor de 32 bits en porciones de 4 bits cada una, este ciclo está entre la etiqueta lee_binario: y la instrucción loop lee_binario. Para extraer los 4 bits mas bajos del registro EDX se hace un AND entre este y EBX que poco antes fue cargado con el valor 0Fh (quince decimal y 00001111 en binario) El resultado de este AND deja en EBX los 4 bits mas bajos del registro EDX y el resto los pone a cero. Esto es lo que los programadores de ASM llamamos “máscara de bits”.
Ahora viene lo interesante: Para convertir esos 4 bits en un dígito ASCII con una sola instrucción de lenguaje Ensamblador usamos EBX como offset del arreglo digitos. De modo que estos 4 bits (que solo pueden tomar valores entre 0 y 15) nos den la posición de memoria de su correspondiente dígito ASCII una vez que se sumen a la posición de memoria indicada por la etiqueta digitos. La instrucción que hace esto y guarda el resultado en la parte baja del acumulador EAX es MOV AL, [EBX + digitos]
Luego de esto, el acumulador completo se guarda en el stack con push y luego se hace un desplazamiento binario hacia la derecha de 4 bits en EDX con SHR EDX, 4. Con esto ahora los 4 bits mas bajos en EDX corresponden al siguiente dígito hexadecimal a transformar. Esto se repite 8 veces hasta que se obtienen todos los valores ASCII para formar la cadena hexadecimal de 32 bits.
La siguiente es bastante sencilla, primero se carga en ECX otro 8 para escribir los 8 digitos del hexadecimal de 32 bits. A continuación se carga en el registro EDI (Extended Destination Index) la posición de memoria de la zona donde vamos a escribir la cadena ASCII. Entonces, por cada ciclo vamos a ir sacando valores de la pila con POP EAX y escribimos los 8 bits mas bajos en la posición guardada por edi con MOV [EDI], AL e incrementamos el ‘puntero’ EDI con INC EDI para ir avanzando en la cadena.
Luego de estos 2 ciclos restauramos los registros generales con POPA y devolvemos el control al llamador con RET. Es importante siempre restaurar los registros generales en Windows, sobre todo EBX, ESI y EDI antes de que el Windows vaya a hacer cualquier cosa, de lo contario podemos desatar su ira y nos echará abajo la aplicación.
Una cosa mas, por si no lo han notado en el primer ciclo los digitos de 4 bits se leen comenzando por el menos significativo pero a la hora de escribir se comienza por el digito mas significativo. Esto es posible porque usamos el Stack. Y como todos saben de la clase de ensamblador con Solis el primer elemento en entrar a estas estructuras es también el último en salir.
Ya para terminar, es importante poder convertir enteros binarios en cadenas ASCII porque la mayor parte de los sistemas operativos (o en este caso la API del Windows) no pueden representar números binarios facilmente. Además de que un mismo número binario puede ser representado en muchas formas diferentes dependiendo del sistema numérico (decimal, hexadecimal, fraccionario, etc.) mas adelante veremos como desplegar un número binario en formato decimal. En realidad solo basta con agregar 2 instrucciones y un dato de 1 byte a este mismo código. Les aconsejo que sean organizados con sus viejos códigos y los reutilicen tanto como les sea posible porque los programas escritos en ASM pueden llegar a ser enormes en source aunque su ejecutable tan solo mida unos pocos kilobytes.
¡Quiero Ver Mas Allá de lo Evidente!
–Crackeando tutorial de Iczelion con OllyDbg–
En esta nota procesaremos el primero de los tutoriales de Iczelion, aunque en realidad vamos a comenzar por el segundo porque la primera parte de lo único que habla es de como funciona el MASM. Y como hay mas gente que habla inglés de la que sabe ensamblador, mejor pasamos a los códigos.
Para esta parte, la mayoría de ustedes ya leyeron la parte teórica, asi que no voy a volver a explicar cosas como para que sirve el .386 (no es la entrada al Modo Protegido) ni lo del modelo flat y stdcall ni los includes ni lo de optioncasemap. Además de que nada de esto nos va a servir. La parte de la sección de datos que tiene 2 cadenas ascii no es la gran cosa y si han seguido este blog desde el principio ya han de saber lo que es una cadena ASCII-Z. Lo único que nos interesa son estas 2 lineas:
invoke MessageBox, NULL,addr MsgBoxText, addr MsgCaption, MB_OK
invoke ExitProcess,NULL
¿Parece sencillo? ¡No lo es! Lo mismo dijeron muchos que intentaron descifrar los tutoriales de Iczelion y ahora viven de hacer querys de SQL. Ese invoke no es una operación de CPU sino una horrible macro, y el primer renglón en realidad se “desenrolla” en 5 instrucciones que en su totalidad miden 18 bytes. Sin contar que a su vez tiene dos llamadas a otra macro anidada llamada ‘addr’ Esta última puede convertirse en 3 o 4 instrucciones mas cada vez que aparece dependiendo de la complejidad de los operandos.
El segundo invoke se desenrolla en solo 2 instrucciones que en total miden solo 7 bytes.
Bueno, los 2 invokes es lo último que ven muchos programadores antes de frustrarse e irse de DBA’s. Pero nosotros tenemos el depurador OllyDbg y al comando de:
OllyDbg, ¡Quiero ver mas allá de lo Evidente!
Obtenemos esta vista del demo de Iczelion en lenguaje máquina:

00401000 >/$ 6A 00 PUSH 0 ; /Style = MB_OK|MB_APPLMODAL 00401002 |. 68 00304000 PUSH msgbox.00403000 ; |Title = "Iczelion's tutorial no.2" 00401007 |. 68 19304000 PUSH msgbox.00403019 ; |Text = "Win32 Assembly is Great!" 0040100C |. 6A 00 PUSH 0 ; |hOwner = NULL 0040100E |. E8 0D000000 CALL ; \MessageBoxA 00401013 |. 6A 00 PUSH 0 ; /ExitCode = 0 00401015 \. E8 00000000 CALL ; \ExitProcess 0040101A .-FF25 00204000 JMP DWORD PTR DS:[<&KERNEL32.ExitProcess>; kernel32.ExitProcess 00401020 $-FF25 08204000 JMP DWORD PTR DS:[<&USER32.MessageBoxA>] ; USER32.MessageBoxA
Como pueden ver, y si no pueden mas abajo lo reescribí en texto para que sea mas sencillo de lamear, las macros se desenrollaron y se convirtieron en instrucciones de ensamblador, las constantes se convirtieron en simples números y además podemos ver las posiciones de memoria del programa.
Para los que ven por primera vez algo como esto, la primera columna indica las posiciones dentro de la memoria virtual, la segunda son los OpCodes en Lenguaje Máquina y la columna que parece código es en realidad código desensamblado. Hasta donde puede, OllyDbg intenta averiguar lo que el programa está haciendo y escribe comentarios en el extremo derecho del código. En este caso, supo que estábamos llamando a MessageBox y Exit Process e incluso identificó plenamente los parámetros. Ahora veamos paso por paso lo que el programa está haciendo:
6A 00 PUSH 0
Aquí están empujando un cero de 32 bits al stack. Esta es la constante MB_OK que le dice a MessageBox el estilo de caja.
68 00304000 PUSH msgbox.00403000
En esta linea están empujando al stack la posición de memoria de la cadena ASCII-Z que dice “Iczelion’s tutorial no.2”. Esta posición es 403000. Pero en el source se usa la etiqueta MsgCaption. La macro addr en este caso no hizo nada porque 403000 es una posición de memoria absoluta. Cuando se usan direcciones relativas como esp + 123h o ebx + edi, addr convierte estas posiciones relativas en absolutas con el uso de la instrucción LEA (esta será motivo de otra entrada)

En esta captura de pantalla se ve el segmento de memoria en ascii y hexadecimal. Si conocen de memoria el código ASCII pueden leer las cadenas directamente. Noten el cero binario con el que terminan y la posición de memoria a la que hacen referencia las funciones que usan texto.
00401007 |. 68 19304000 PUSH msgbox.00403019
Esta linea hace lo mismo que la anterior pero manda al stack la posición de la cadena ascii que dice: «Win32 Assembly is Great!»
0040100C |. 6A 00 PUSH 0 ; |hOwner = NULL
En esta linea se empuja otro cero al stack que le dice a MessageBox que la ventana no tiene padres, pues hOwner indica el handler del Pwner Owner o dueño de la ventana. Este cero indica que aparece en el centro del escritorio. Pero eso ya es cosa de la API de Windows
0040100E |. E8 0D000000 CALL <JMP.&USER32.MessageBoxA> ; \MessageBoxA
Aquí se llama a MessageBoxA. Nótese la A mayúscula que va al final. Para Windows hay diferencias entre funciones ascii y unicode. En este caso llamamos a MessageBox versión ASCII. Otra de las cosas importantes que nos ocultan las macros.
00401013 |. 6A 00 PUSH 0 ; /ExitCode = 0
Esta ya es parte del segundo Invoke, aquí se empuja un cero al stack que es el único parámetro de la función ExitProcess que termina el programa. La constante NULL se transforma en cero, parece que NULL es mas sencillo de leer en un código que el propio cero.
0040101A .-FF25 00204000 JMP DWORD PTR DS:[<&KERNEL32.ExitProcess>; kernel32.ExitProcess
Finalmente se llama a la función API de windows ExitProcess y se termina el programa. La linea que sigue pertenece un sistema de llamado de funciones conocido como JUMP TABLE o trampolín. Que permite que un programa pueda llamar funciones externas y cambiantes sin necesidad de reprogramación. En esta tabla se colocan los verdaderos llamados a función y cuando hacemos un CALL para ejecutar una función API lo que en realidad hacemos es saltar a esta tabla. Este es un mecanismo interesante pero no hay urgencia de verlo porque FASM no lo usa. De hecho, este programa hace exactamente lo mismo que el PEDEMO.ASM que viene en los ejemplos del fasm y en este mismo blog en la nota llamada “¡Al fin un código!”
Hasta ahora, apenas hemos entendido lo que realmente ocurre tras esos inocentes invokes, y ya tienen una idea de lo peligrosas que pueden ser las macros para los principiantes, es mejor que las guarden para cuando tengan artritis y no puedan teclear sus programas los suficientemente rápido. O por lo menos hasta que realmente sepan lo que están haciendo y lo confirmen con el depurador de códigos en la primera oportunidad.
Para recapitular, hoy aprendimos todo esto:
1.- Se necesita un depurador para entender los tutoriales de Iczelion.
2.- Una macro puede desenrollarse en muchísimas instrucciones de Ensamblador
3.- Los argumentos de una función se introducen por el STACK en orden inverso a como quedan dentro del stack frame.
4.- Las constantes como MB_OK, hOwner, etc. Se convierten en simples números enteros casi siempre de 32 bits
5.- La macro ADDR convierte una referencia a memoria de tipo relativa a una posición de memoria absoluta usando la instrucción LEA.
6.- En este caso se usa una JUMP TABLE para hacer las llamadas a la API de Windows, pero FASM no trabaja asi.
Por ahora me regreso a donde estaba, estoy desarrollando una trampa para lamers muy divertida, aunque va a estar lista para la siguiente temporada de caza y esta es hasta el final del otoño. Por ahora traten de leer y analizar los tutoriales de Iczelion ustedes solos a ver que mas se encuentran, recuerden que hay un link a la web de Iczelion a la derecha de este blog.
IEEE 754 y los Juegos 3D
–Importancia del Punto Flotante en los Videojuegos–
###ESTA NOTA AUN NO ESTA TERMINADA NI SERA LA ULTIMA ACERCA DEL PUNTO FLOTANTE O IEEE 754###
Hasta donde recuerdo, el primer juego que exigía una unidad de punto flotante para funcionar fue Quake de Id Software. O al menos ese fue el primer juego que necesitaba un procesador Pentium de Intel como requerimiento mínimo.

¿Pero que tiene que ver uno de los mas famosos juegos para computadora con un aburrido circuito electrónico que solo sabe hacer cuentas? Resulta que para hacer los cálculos para las gráficas 3D es necesario una gran velocidad y precisión numérica. Y aunque es posible hacer gráficas respetables usando “fixed point” (a los estándares de los noventas), desde el punto de vista de un procesador Intel es mas rápido y eficiente trabajar con números de punto flotante. Aunque antes de empezar a detallar el funcionamiento de una FPU, es necesario aclarar algunos términos básicos: Para empezar. ¿Porqué demonios se le llama unidad de punto flotante?
Flotante significa que sube y baja y que no se mantiene al mismo nivel, tal y como lo hace un barco de papel que flota en el agua. Contrario a lo que sucede con el punto fijo o Fixed Point. Donde el punto que separa a los enteros de las fracciones se mantiene mas o menos en el mismo lugar o casi no se mueve. El simil en el mundano sistema decimal son los números de notación científica. Esos que tienen un número con un punto una cifra chiquitita que les cuelga por un lado. Para quienes fueron a la escuela pública aquí va un ejemplo sencillo:
2.345 x 10^6
Lo que nos dice esta expresión es que al número 2.345 hay que multiplicarlo por 10^6. Como 10^6 es un millón (1,000,000) la multiplicación es 2.345 x 1,000,000 que nos da un fabulosos total de 2,345,000. Para quien tiene mas de 2 dedos de frente es obvio que no era necesario hacer todo este cálculo, solo bastaba con ‘correr’ (como dirían en españa) el punto 6 lugares hacia la derecha. Si el exponente de la base 10 es negativo, entonces habría que deslizarsa hacia la izquierda. Y si el exponente fuera cero el punto se quedaría donde está.
Sin embargo, dentro del mundo de la computación no existe el sistema decimal, todo se hace en binario. Si recuerdan la nota de “El Partido por la Mitad” sabrán como se representan las fracciones en este sistema. Sin embargo, la mayor parte de lo que se aplica para la notación científica decimal tambien cuenta para la notación exponencial binaria. En este gráfico vemos como se almacena un flotante de 32 bits:
***aqui deberia de ir un dibujo de un flotante de 32 bits***
Veamos cada parte del número:
Signo.- Es el bit mas alto, pero se interpreta diferente que los enteros con signo. Aquí simplemente indica que el valor es positivo (bit = 0) o negativo (bit = 1)
Exponente.- Es un número entero signado. En este caso mide 8 bits y puede representar de -128 a + 127. No hay que olvidar que en los números de punto flotante la base es 2. Un exponente debe de ser polarizado (biased) para evitar errores en el cálculo de recíprocos.
Mantisa o Significando.- Son los últimos 23 bits. (aunque funciona como si fueran 24) El tamaño del significando determina la precisión de los números de punto flotante. Pues aunque es posible representar valores con exponente tan grande como 2^ 255. Mas allá de 16,777,216 o de 1 / 16,777,216 comienza a perderse precisión.
Ahora veamos un ejemplo clásico del libro de Brey. El número decimal 100.25 a formato de punto flotante:
Tenemos 100.25
Convirtamos la parte entera a binario del método tradicional:
comienza con 100
0110 0100
convertir a binario la parte fraccionaria es diferente. A la fracción le vamos restando potencias negativas de 2. Si se puede restar se resta y se escribe un uno y si no se escribe un cero. Seguimos el proceso hasta que la fracción se iguala a cero o hasta que se nos acaben los bits para representarla.
0.25 – 0.5 <0 ——- 0
0.25– 0.25 >= 0 —-1
0.01
Entonces, l00.25 es 01100100.01
Como sabemos, multiplicar un número por un valor elevado a la potencia cero no lo altera sin importar porqué valor se multiplique, entonces
01100100.01 == 01100100.01 x 2 ^ 0
El último paso es deslizar el punto hasta la derecha del primer número UNO. Esto equivale a multiplicar el número por una potencia de 2 (Recuerden que una división es en realidad una multiplicación por un valor con exponente negativo) y hay que ajustar el exponente del 2 de acuerdo con ese movimiento:
01.10010001 x 2 ^ 6
Esta notación significa: Multiplicar el valor 01.10010001 por 2^6. Lo que nos da 01100100.01 que es el valor en formato binario de punto fijo.
Bueno, hasta ahora apenas hemos visto como convertir valores con decimal a notacion científica binaria. Pero no hemos visto nada sobre valores de punto flotante. Para hacer esto, aún hay que hacer algunas modificaciones:
El signo pasa directamente.- Solo va 0 si es positivo y 1 si es negativo.
El exponente debe ser polarizado (biased).- Para evitar desbordamientos a la hora de obtener el recíproco de un número es necesario polarizarlo. Esto se hace sumándole el mayor entero positivo. En este caso 7F hexadecimal para 8 bits. Esto permite cambiarlo de signo impunemente sin necesidad de preocuparse por un desbordamiento causado por el Wrap-Around. Si miran el Yin-Yang binario (la rueda azul y roja de la nota Positivo y Negativo) verán que este proceso manda el cero a la parte baja del círculo que representa los valores con signo.
Al significando se le quita el bit J.- Como ya saben desde sus años en la primaria pública. A la izquierda del punto que separa los enteros de las fracciones, siempre debe de haber un número diferente de cero. En el caso decimal puede ser cualquier valor del 1 al 9. Pero en binario, este valor solo puede ser UNO. Y si el valor no es uno, entonces el exponente no está bien definido. Ese bit es llamado “Bit J” en los manuales de Intel. De este modo, solo los 23 bits que siguen al punto se escriben en el formato. Los bits a la derecha se rellenan con ceros.
***tengo pendiente poner aqui la construcción del valor flotante***
Pero las cosas no son tan sencillas. En el mundo del punto flotante existen una gran cantidad de bestias extráñas que solo quien programa en Ensamblador puede verlas cara a cara. Algunas de estas son:
NaN’s.- Es cuando una operación da un resultado que no puede ser representado por los números reales. Como la raiz cuadrada de un valor negativo.
Infinito.- Es posible representar el infinito en formato de punto flotante.
Números denormales.- Hay una zona de la recta numérica real que no puede ser representada adecuadamente en formato de punto flotante. Para evitar esto la FPU manda una señal cuando detecta esta condición.
Zona de baja precisión.- El rango de números reales que pueden ser representados en punto flotante es similar a un resorte. Si el resorte está comprimido no hay espacio entre los anillos que forma la espiral pero conforme lo estiramos se van creando huecos. Del mismo modo, hay zonas en las que esos huecos son tan grandes que hay una gran pérdida de datos debida al redondeo.
Bueno, esta nota ya se extendió demasiado. Otro día seguiré con un estudio de esta clase de fenómenos.
+++ Positivo y Negativo – – –
–Números Binarios Con y Sin Signo–
Hasta ahora, la entrada de este blog que ha sido mas leida es la de ¿Cuantos bits tiene un Byte?. En esa entrada se deja en claro lo que es un byte. Una celda de 8 bits que puede almacenar cualquier número entero entre 0 y 255.
Sin embargo, cada uno de estos valores puede ser interpretado de 2 maneras diferentes dependiendo del contexto en que se trabaje.
Números sin signo.- Estos son los de siempre. Cuenta de cero a 255.
Números con signo.- Con los mismos 8 bits de un byte, podemos representar los números desde el -128 al 127. Si se fijan, estos son 256 valores diferentes.
Todos estos conceptos son suficientemente complejos para que se les dedique un examen completo en una carrera de Ingeniería en Computación. Sin embargo, en este dibujo que recuerda a un Yin-Yang chino pueden verse la mayoría de los conceptos que tienen que ver con esto de los números enteros con y sin signo:

Este círculo se lee exactamente igual que un reloj analógico. (De manecillas) Se parte del punto mas alto donde está el valor 0 y se recorre toda la circunferencia hasta llegar a donde empezamos. De hecho, al igual que el reloj, la cuenta que lleva un byte vuelve a comenzar al dar una vuelta completa. Este fenómeno se llama WRAP-AROUND y es la base de la aritmética de enteros signados, (que no es lo mismo que santiguados). Este fenómeno era muy común en los juegos de principios de los años 80 como Asteroids, en donde si uno salía por un lado de la pantalla, magicamente aparecía por el lado de la pantalla opuesto.
Sin embargo, las similitudes con el reloj convencional terminan aquí. Pues esta rueda puede moverse en sentido opuesto a como lo hacen las manecillas. Pues del mismo modo que si tenemos 255 y le sumamos uno el contador se reinicia en cero, si tenemos cero y restamos uno, el contador marcará 255. Esto tiene perfecto sentido en los números sin signo, representados aquí en color gris tanto en decimal como en Hexadecimal. Entonces, para dar una vuelta completa al circulo, hay que dar 256 pasos. Pero eso es solo porque esta representación es de 1 byte.
Números con signo.- Cuando usamos signo, la mitad de los números son positivos y la mitad negativos. Aunque hay 2 casos especiales:
Cero Positivo.- Aunque matemáticamente el cero no es ni positivo ni negativo, y puede dividirse entre cualquier número. Dentro de un CPU un cero se considera positivo y par. Pero esto es válido solo para las representaciones de números enteros, pues en Punto Flotante pueden representarse ceros positivos (porque tienen SIDA) y negativos para su uso en cálculo infinitesimal. El cero siempre tiene todos los bits puestos en cero sin importar si se trata de un registro de 8, 16, 32, 64, etc. En el diagrama, el cero se encuentra en la parte mas alta del círculo del lado positivo (azul).
El Gran Negativo.- El -128 es el número negativo con mayor valor absoluto que puede representarse en 8 bits. Para compensar el hecho de que los negativos no tienen cero, los positivos no tienen el +128. El número negativo con mayor valor absoluto puede ser:
-128 en 8 bits,
-32768 en 16 bits,
-2,147,483,648 en 32 bits
y -9,223,372,036,854,775,808 en 64 bits.
En realidad no importa el ancho del registro, el Gran Negativo siempre se representa con todos los bits en cero excepto el bit mas significativo. En el diagrama, el Gran Negativo se encuentra en la parte mas baja del círculo, del lado negativo (rojo).
Lo interesante es que la computadora no sabe ni le importa si el valor en el registro tiene signo o no. Si en la parte baja del acumulador hay un A0h el CPU no sabe si se trata de un 160 sin signo o un -96 con signo. Mas adelante veremos como el CPU evalúa un resultado con el registro EFLAGS. Los números entre el 0 y el 127 con signo se manejan igual a los que no tienen signo.
Bit Signo.- Es el bit mas alto del registro. Si está en uno el valor es negativo y se está en cero es positivo. Podría decirse que ese es el ‘bit del mal’. Pero ojo, si queremos convertir un número positivo a negativo, o viceversa, hace falta mucho mas que solo cambiar el valor de este bit. Hay que ‘negarlo’ con la instrucción NEG.
NOT.- Esta operación es muy simple, enciende todos los bits apagados y apaga todos los bits entendidos. En el círculo, esta operación funciona como un espejo,pues solo hay que trazar una linea horizontal desde el valor que queremos hacerle el NOT hasta el otro lado de la rueda. Pero Ojo, los números no son simétricos. La suma de cualquier número mas su valor NOT es igual a todos los bits activos, en este caso -1 con signo y 255 con signo.
NEG.- La instrucción NEG cambia el signo de un valor entero. Si es positivo lo hace negativo y el negativo a positivo. Para que no se les olvide, el NEG es como una opreración de cambio de sexo (u operación jarocha como diríamos en México).Primero hace un NOT y luego suma un uno. Esto se ve en el círculo donde están las flechas azul y roja y la palabra NEG. Se traza una linea hasta el otro lado de la rueda y se avanza una unidad para cambiar el signo. Pero hay 2 excepciones: El Cero y en Gran Negativo. Si le aplicamos el NEG a cualquiera de estos 2 valores no sucederá nada. Tan solo se activará la bandera CARRY en el registro EFLAGS.

Por último, hay que dejar claro que para el CPU hay una gran diferencia entre el hecho de que un número sea mayor o menor que otro y que esté por encima o por debajo de otro. En este otro dibujo vemos el mismo círculo de la primera ilustración en forma ‘desenrrollada’ y podemos ver lo complicado que resulta representar números con signo de manera no circular.
El concepto de MAYOR y MENOR solo aplica para los números con signo. Mientras que ARRIBA y ABAJO es solo para los que no tienen signo. Por ejemplo, el -1 es menos que 100 pero a la vez -1 está por encima del 100 porque -1 es 0FFh mientras 100 es 64h. Esto tiene una ventaja, si queremos ver si un resultado está entre 0 y 50, en lugar de hacer 2 comparaciones (resultado < 0 y resultado > 50) hacemos solo una, donde vemos si el resultado está por debajo del 50. Pero esto ya es asunto del registro EFLAGS.
De acuerdo, ya me extendí demasiado. Para acabar solo queda decir que no hay que confundir el Carry con el Overflow. Supongo que ya debería de hablar de como toma decisiones la computadora. Pero por ahora a insultar:
Hace unas horas eché un vistazo al circo de pulgas. Es increible como llevan casi un mes tratando de unir todos los archivos de sus sprites lameados con alguna aplicación. Al parecer alguien se queja de que la única aplicación que encontró para hacer esto solo los ordena de modo vertical. ¡Estos lamers no saben que en esa disposición es mas sencillo su almacenamiento y recuperación en la memoria! Quieren que el programa acomode los sprites en una matriz bidimensional donde todos los sprites quedan en celdas del mismo tamaño. De hecho en el foro viene una secuencia de animación de un Ha-Do-Ken. (Suerte que esta vez no le dijeron ‘abuken’) y cada cuadro de animación es por lo menos 9 veces mas grande que el sprite que contiene. Lo que significa que, como no creo que sepan nada de compresión en tiempo real, van a gastar 9 veces mas memoria solo en esa animación. En otro thread, al parecer están planeando una orgía. Pero eso ya no tiene nada que ver con la programación. Bueno, ahí le dejo porque tengo que planear nuevas bromas crueles para este blog.
El Partido Por la Mitad
–Como representar fracciones en código binario–
1 + (½) + (¼) + (1/8) + (1/16) + (1/32) +(1/64) + (1/128) + …
No importa cuantos terminos le agreguemos a esta suma. ¡Nunca va a llegar a dos enteros! Los matemáticos llaman a esto ‘convergencia’. Se dice que esta suma converge en 2 cuando la cantidad de términos es infinita. Por ahora no nos importa demasiado el estudio de las series infinitas, pero esta expresión es la base para entender como demonios hace la computadora para representar fracciones.
Recordemos un poco la importancia de las potencias de 2 en computación. Sabemos que podemos obtener cualquier valor entre 0 y 255 (un byte) unicamente con los números 1, 2, 4, 8, 16, 32, 64 y 128 sumándolos y sin repetir uno solo. Estas son potencias positivas de 2, incluyendo 2^0. Del mismo modo podemos aproximar fracciones con potencias negativas de 2. 2 a la cero mas las 7 primeras potencias negativas de 2 son:
2^(0) = 1 = 1
2^(-1) = ½ = 0.5
2^(-2) = ¼ = 0.25
2^(-3) = 1/8 = 0.125
2^(-4) = 1/16= 0.0625
2^(-5) = 1/32 = 0.03125
2^(-6) = 1/64= 0.015625
2^(-7) = 1/128= 0.0078125
Si sumamos todos estos términos obtenemos 1.9921875. Y si a eso le sumamos la fracción negativa mas pequeña obtenemos ¡2!. Del mismo modo que si tenemos 1.999 y sumamos 0.001 nos da 2. Pero para entender mejor y de paso hacer este blog un poco menos gris aquí les dejo un dibujo en Paint:

En este dibujo queda claro como se representa un entero como una suma de potencias negativas de 2. En este caso, la n representa la cantidad de términos que usamos para representar el entero. Mientras mas términos usemos el resultado tendrá mas precisión.
Bueno, ahora que ya sabemos como se expresan las fracciones en el sistema binario solo falta explicar para que sirve esto:
Para nosotros este es el primer paso en estudiar la aritmética de punto flotante, la cual no solo se usa para calcular los centavos de la variable sueldo, sino que tiene enormes aplicaciones en campos tales como las gráficas 3D, CAD, gráficas 3D, cálculos científicos, gráficas 3D, medicina, gráficas 3D, astronomía, gráficas 3D, posicionamiento global, gráficas 3D, datos estadísticos, gráficas 3D, y cualquier otro campo en el que se necesite de la alta precisión de la notación científica como por ejemplo en las gráficas 3D.
El primer paso en esto de las fracciones binarias es lo que llaman “fixed point math” o matemáticas de punto fijo. Se maneja exactamente igual que el punto decimal que aprendimos en educación elemental. El problema es que hay que tener buena memoria porque el CPU no sabe lo que estamos haciendo. En el caso de las sumas y restas basta con alinear los registros con las instrucciones SHL y SHR. En el caso de las multiplicaciones enteras estos desplazamientos de punto fijo se suman, pero si uno es listo puede tomar en cuenta que por ejemplo, si multiplicamos 2 registros de 8 bits el resultado es de 16 bits. Es posible manipular el punto fijo no solo con SHL y SHR, sino direccionando partes independientes del registro. O para casos de números muy grandes podemos usar SHLD.
A principios de los noventas las contadas gráficas en 3D se hacían con este tipo de aritmética binaria de punto fijo. No parecía la gran cosa ¡pero era suficiente para que la PlayStation desplegara sus famosas gráficas 3D!. Pues esta consola no incluía una unidad de punto flotante. Inclusive, la antigua tecnología MMX de los procesadores Intel permitían hacer aritmética de punto fijo en forma vectorial.
Y no se fien, puede que lleguen a usar técnicas ‘fixed point’ si es que acaso llegan a programar un sistema que no tenga una unidad de punto flotante, como la mayoría de los celulares o consolas portátiles de bajo costo. Mas adelante veremos como las computadoras representan la notación científica: La aritmética de punto flotante…
La Porrista de 100 Kilos
–Direccionamiento Base con Indice Escalado y Desplazamiento–
Direccionamiento de memoria. Esta es la parte mas confusa a la hora de programar en Ensamblador. Pues los registros generales no solo sirven para contener bits. También se usan para mover datos entre la memoria y el CPU. Del mismo modo que podemos usar una mano para sostener algo o podemos señalar con el dedo. Sin embargo, un CPU de Intel es capaz de combinar sus registros generales de forma que puede guardar y recuperar datos de las estructuras mas extrañas con gran eficiencia.
Esto es muy similar a esas pirámides humanas que hacen las porristas de los eventos deportivos. Donde las mas fuertes se apoyan en cuatro en el suelo. Las de mayor equilibrio se paran sobre sus espaldas y la mas agil de todas trepa hasta la punta y salta realizando una vistosa pirueta en el aire…
Bueno. Como ya me está comenzando a sangrar la nariz mejor le sigo con el Ensamblador. Los registros del CPU pueden ser usados para ‘apuntar’ a la memoria. Quienes han programado en C de seguro escucharon alguna vez el concepto de ‘punteros‘. Los punteros son variables que contienen posiciones de memoria (que al fin y al cabo siguen siendo bits). Un CPU de Intel puede hacer aritmética de punteros ¡Por Hardware!. Aunque puede verse como algo muy complicado. Solo consiste de 3 partes: Base, indice y desplazamiento. Aunque estos nombres son los oficiales de Intel no necesariamente son los mas acertados y veremos porqué.
BASE.- Es el registro sobre el que se apoya el índice. En la pirámide, sería la porrista que está enmedio. Su contenido puede ser cambiado y con ello se pueden lograr direccionamientos relativos. Esto es lo que hace funcionar las variables locales en un Stack Frame.
INDICE.- Es el que está hasta el final. Se apoya sobre el registro base. La porrista que está en la punta de la pirámide y hace las acrobacias. Su contenido puede cambiarse y avanzar por las partes mas recónditas de las estructuras.
DESPLAZAMIENTO.- Es la parte constante del direccionamiento. Se trata de un número que puede ser una posición absoluta de la memoria o relativa a otro registro. Sin embargo, su valor no puede cambiarse sin cambiar el código máquina de la instrucción. El mejor uso de esta parte es para apuntar a posiciones fijas de la memoria como son las variables globales o el principio de un gran arreglo de estructuras. Por analogía con las porristas. El desplazamiento sería: ¡La Infame Porrista de Cien Kilos! Quien por su peso no puede moverse ni mucho menos pararse sobre la pirámide. Por seguridad, la posición que le toca a esta gorda es la de soporte de la piramide.
Un direccionamiento completo con estos tres elementos se vería así:
MOV EAX, [EBX + ESI + 1234h]
Esta instrucción suma el contenido de los registros EAX, ESI y el valor 1234 hexadecimal. Esto da un número que corresponde a una posición de memoria. Entonces, el valor de 32 bits almacenado en esa posición de memoria se almacena en el registro EAX. Pero aún hay mas. Algo llamado factor escalar.
Como recordarán, el valor de las posiciones de memoria es una cantidad en bytes. Los bytes son celdas de 8 bits. No de 16, 32 ni 64. Solo 8 Entonces, ¿Que pasa cuando tenemos que trabajar con valores que no son de 8 bits? Un programador inexperto y desconfiado usaría operaciones aritméticas como ADD; Uno igual de inexperto pero con mas seguridad en si mismo recurriría a la instrucción SHL. Pero alguien que realmente separ de programación sabe que puede usar factores escalares. Un factor escalar en un direccionamiento de memoria multiplica por 2 (16 bits), 4(32 bits) u 8 (64 bits) única y exclusivamente al registro índice. De este modo, es posible recorrer todos los valores internos de una estructura.
De nuevo, con el ejemplo. El valor índice marca que tan alto es el salto que debe de dar la porrista que está hasta arriba de la pirámide.
Ahora al código máquina:
Esto parece demasiado complicado. Sin embargo. Cuando vemos el formato del código máquina todo se aclara. Y aquí es donde entra el byte SIB. Que es el acrónimo de Scalar Index Base. He aquí los bits:
Bits[7:6].- 2 bits que indican el factor escalar. 00 es 0; 01 es 2; 10 es 4 y 11 es 8. Para quien le entienda a las matemáticas, estos son las potencias de 2: 2 ^ 0= 1; 2^1 = 2; 2^2 = 4 y 2^4 = 8.
Bits [5:3].- 3 bits que indican el registro índice. Se interpretan de manera CASI igual que el campo REG de ModR/M. Pero hay pequeñas diferencias que pueden meternos en lios. Recuerden que solo el Indice se puede escalar. Nótese que ESP no puede ser un Indice escalado.
Bits[2:0].- 3 bits que representan la base. De nuevo se interpreta CASI igual que REG en ModR/M. Sin embargo. La combinación binaria 101 (5 decimal) y que correspondría a ESP, se interpreta diferente dependiendo de los 2 bits [5:7] Del byte ModR/M. Para mas detalles vean el dibujo.
Para terminar, cabe mencionar que los bytes ModR/M y SIB trabajan juntos. La existencia e interpretación de SIB depende directamente de ModR/M y este a su vez del OpCode. Además, algunas instrucciones utilizan una parte de ModR/M como parte del código de operación. Un ejemplo de esto es la instrucción DEC cuyo equivalente en C sería el “- -”. El campo REG del byte ModR/M de esta instrucción siempre es 001. Aunque tiene una forma que solo usa un byte.
Mas adelante explicaré como conectar OpCode, ModR/M y SIB. Pero por ahora, ya tienen suficiente para explorar por cuenta propia el código máquina de un programa para los procesadores de Intel. Y ahí si, si logran comprender, no necesitarán a nadie que les eche porras (espero que los programadores brasileños no se ofendan por esta expresión), y mucho menos a una porrista de cien kilos.
Operandos
–Como se representan los operandos en lenguaje máquina–
Este asunto del blog me ha mostrado la gran diferencia que existe entre saber sobre un tema y poder explicarlo. En este caso, también he visto la utilidad de los dibujos para explicar los conceptos mas difíciles. Hasta ahora me la he llevado bien con el Paint del Windows. Sin embargo, algunos diagramas son tan grandes y complejos que, aunque técnicamente es posible hacerlos en Paint, me tomaría demasiado tiempo y el resultados sería tan enredado que de poco le serviría a quien los viera. Supongo que el Paint en este caso funcionará como una especie de candado. De este modo no generaré dibujos demasiado complejos que solo quitan tiempo a quien los hace y los mira. Asi como ocupan espacio en los servidores.
El tema del que quería hablarles hoy es sobre los OpCode Maps. Un OpCode Map es un mapa de todas las combinaciones posibles que pueden tomar los códigos máquina de un CPU y se puede desplegar en un arreglo bidimensional semejante al de un tablero de ajedrez. En el caso de los procesadores de Intel, Este mapa tiene 3 pisos, además de que se divide en otros mapas mas pequeños. En este caso, vamos a movernos desde los mapas mas pequeños a los mas grandes.
En este caso, el mapa mas pequeño y mas útil que conozco se llama Mod/RM.
Mod/RM es un BYTE que controla la combinación de los operandos de una instrucción. Si uno comprende esto del Mod/RM, ya no se va a enredar con la lógica de los operandos. Que si registro con registro, registro con memoria, base mas índice, etc. Pues aunque matemáticamente es posible hacer un número estratosférico de combinaciones, el byte Mod/RM solo puede asumir 255 valores diferentes.
Para empezar es bueno aclarar porqués esta cosa se llama Mod/RM. Y es porque este byte define el modo de acceso, y la combinación de registros y registro/memoria. No se preocupen, para lo único que necesitarán saber esto es para saber que combinaciónes de operandos son válidas y cuales no. A menos que quieran hacer su propio ensamblador o que quieran escribir operaciones en código máquina puro nada mas para fastidiar.(Cosa que veremos aquí: ver código puro y fastidiar).
A grandes rasgos el byte Mod/RM se divide en 3 partes, aunque en realidad son solo 2 pero una está partida:
bits [7:6].- Son los 2 bits mas altos del valor RM
bits [5:3].- Bits que indican un registro de CPU (puede ser general, mmx, simd, etc)
bits [2:0].- Los 3 bits mas bajos del valor RM.
La parte mas sencilla de comprender son los 3 bits que indican un registro. Como sabemos, en el modo de ejecución de 32 bits. (Y también en el de 16 pero no se lo digan a los lamers) tenemos 8 registros de propósito general. Y también sabemos que con 3 bits podemos representar 8 combinaciones que son los números del 0 al 7. En esta colorida tablita les dejo el valor máquina de los registros generales:

Aunque ya había hablado sobre esto en la nota ‘Los 8 jinetes del Apocalípsis, es hasta que uno ve esta tabla el porqué es importante aprenderse los registros en ese orden en particular y no basándose en el alfabeto. Ahora vamos con el campo R/M de 5 bits y a explicar porqué se separa en 2 partes:
MOD.- Estos son 2 bits que representan el tipo de direccionamiento que vamos a usar. Dependiendo de estos 2 bits es como [2:0] han de ser interpretados. Veamos otra tabla de la parte MOD

Como podemos ver, los 4 valores del MOD indican el tipo de desplazamiento constante. Que puede ser cero, de 8, 32 o registro. Cuando los 2 bits del campo mod están encendidos, significa que la operación tiene por argumentos dos registros del CPU. En este caso, los bits R/M que son [2:0] se interpretan del mismo modo que los bits [5:3] del campo REG.
Entre estas entradas hay algo llamado código de escape. Nótese que a menos que los bits MOD estén ambos activos. El trio R/M no puede tomar el valor binario 100 (4 decimal). Este es un código de escape y cuando aparece significa que luego del byte ModR/M sigue el bite SIB.
SIB debe su nombre a Scalar Index Base. Si ModR/M fuera el hermano mayor, SIB sería el hermano menor y si combinamos ambos podemos hacer un direccionamiento de la memoria mas sofisticado. Pero por ahora, prosigamos con el ModR/M.
Para terminar aquí hay algunos puntos relacionados con el byte ModR/M:
*Este byte no trabaja solo. Depende de 2 bits dentro del OpCode de la instrucción (para quienes no leyeron la entrada anterior, un OpCode es un código de operación del CPU. Estos bits son D, W e I. El bit D indica quien es el operando fuente y quien el destino. Si uno se equivoca al activar este bit puede hacer que una operación haga exactamente lo opuesto a lo que quiere. El bit W indica el ancho de los operandos (Wide). De ahí que pueda distinguir entre EAX o AL cuando el campo REG del ModR/M está en cero. En la mayoría de las instrucciónes los operandos deben de ser del mismo tamaño. Con Excepción de las operaciones de extensión como CBW CWD y CDE. Hay un buen chiste sobre este tipo de instrucciones que les contaré cuando veamos el tema y los niños se hayan ido a dormir.
El Bit I indica que uno de los operandos es un valor inmediato. Un valor inmediato es una constante que se pasa como argumento. Es importante tomar en cuenta que siempre los operandos inmediatos son operandos fuente. Nunca se debe poner un valor inmediato como operando destino de una instrucción. Por Ejemplo, para sumar 2 al acumulador hacemos MOV EAX, 2. Pero de ninguna manera podemos hacer MOV 2, EAX.
Como nota histórica, en la antigua era de lo 16 bits. El ModR/M era suficiente para manejar todos los direccionamientos de memoria posibles. Esto se debía a que únicamente se podían usar 3 de los 8 registros generales para apuntar a la memoria. Estos eran BX, SI y DI. Pero ahora todos los registros tienen esa capacidad. Otra cosa nueva es el uso de escalares para direccionar elementos de memoria cuyo ancho fuera mayor que el de un byte sin recurrir a aritmética turculenta que solo retrasa la ejecución. Pero como le dijo la Nana Goya a Conan el Bárbaro:
–Pero esa es una histora para ser contada en otra entrada…–
Mas Máquina que Hombre
–Como programar en lenguaje máquina–
Un programador de Ensamblador que no sabe programar en lenguaje máquina es como un químico que desconoce la manipulación del átomo. También se ha dicho mucho que programar en lenguaje máquina es imposible. Sin embargo, luego de algunos meses de insultar lamers y ver dibujitos en paint, considero que ya están listos para comenzar a hacer tal proeza.
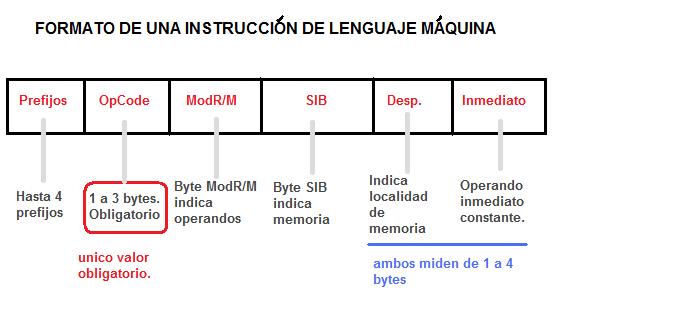
No todos los campos se usan en todas las instrucciones. El único indispensable es el de OpCode. Todos los demás son opcionales.
Veamos un poco que significa cada campo:
Prefijos.- Existen prefijos que modifican las instrucciones. Algunos de ellos son los modificadores de ancho de operando/dirección (66h y 67h), los de repetición para funciones de manejo de cadenas y el temible prefijo REX del que se hablará en otra nota.
OpCode.- Este es el único obligatorio. Una instrucción puede medir desde un solo byte, como por ejemplo un NOP (90h) o hasta 16 bytes como en algunos saltos largos. El campo de OpCode por si solo puede medir entre 1 y 3 bytes.
ModR/M.- Este es un byte que especifica los operandos de la instrucción. Por lo general se pueden expresar las combinaciones de operandos mas usuales tan solo con este, pero a veces es necesario otro byte para direccionamientos mas complejos.
SIB.- Su nombre viene de Scalar Index Base. Es el complemento de ModR/M. Con este es posible hacer combinaciones de registros y desplazamientos que no era posible lograr en los antiguos modelos de 16 bits.
Desplazamiento.- Puede medir entre 1 y 4 bytes. Especifica una localidad de memoria que puede ser absoluta o relativa.
Valor Inmediato.- Semejante al anterior, pero este número se usa para representar un valor inmediato. Un valor inmediato es cuando uno de los operandos de la instrucción es una constante.
Definitivamente tengo que poner un link mas directo a los manuales de Intel.
Ahora a insultar.- Lo primero que han de preguntarse es que gana uno programando en lenguaje máquina. Bueno, ademas de hacer algo que no cualquiera puede hacer y el aumento de la autoestima a lo que esto conduce. Si conocen por ejemplo los bytes ModRM y SIB ya no tendrán dudas sobre que combinaciones son válidas. También es posible activar instrucciones de los procesadores mas recientes sin tener que esperar a que aparezca un compilador que las use. Aunque en mi experiencia personal es mas sencillo construir tu propio ensamblador que hacer programas completos en lenguaje máquina y el resultado es igual de eficiente. Otra gracia que tiene es que cuando las instrucciones cumplen ciertas reglas de alineación dentro de la memoria se ejecutan mucho mas rápido que si solo las aventaras así como van.
Por cierto, este diagrama solo es válido para lo que Intel llama “modo de compatibilidad” es decir que si su sistema Windows es de 64 bits. El formato de la instrucción cambia un poco. En ese formato conocido como “IA-32e”. En ese modo de operación es posible manejar memoria mas allá de la barrera de los 4 Gbytes de manera directa. Aunque la única diferencia entre lo que acabo de explicar y este modo, tan solo es el prefijo REX que va entre los prefijos y el OpCode.
Por último, y nada mas para que se sientan un poco como Neo de Matrix, intenten insertar en el código de siempre algunas instrucciones en lenguaje máquina.
Para insertar una instrucción en lenguaje máquina, hacemos lo mismo que cuando inicializamos una localidad de memoria. Por ejemplo. Supongamos que tenemos este código:
mov eax, 666h
Si mandamos desplegar el contenido del acumulador con una función o usamos un depurador de códigos, veremos que eax contiene el valor hexadecimal 666. Ahora, si modificaramos el código de esta forma:
mov eax, 666h
db 90h
no sucedería nada. Pues db 90h es la instrucción NOP, daría lo mismo si escribiéramos NOP en lugar de 90h. Estanstrucción aperentemente inutil se usa para alinear código y acelerar su ejecución dentro del CPU. Ahora hagamos algo mas visible:
mov eax, 666h
db 90h
db 33h,0c0h
Si ahora desplegamos el contenido de EAX, este mostrará CERO. Esto es porque 33h,0c0h es el código máquina de XOR EAX, EAX. Pone en cero el contenido de EAX y es mucho mas rápida y ocupa un tercio de la memoria que MOV EAX, 0. En realidad no es necesario poner cada instrucción en un renglón. Es posible poner todos los códigos máquina en uno solo o partirnos como queramos. Al final el Ensamblador va a juntarlos todos de manera lineal.
Bueno, ya me extendí mucho, en próximas notas veremos mas sobre el lenguaje máquina y de paso exploraremos un poco el modo de operación de 64 bits. Esperen un pequeño BOOM de notas, porque ya vienen las vacaciones y voy a tener mas tiempo libre para escribir estupideces. Y si se aburren, consiganse la segunda parte de los manuales de intel (Instruction Set Reference) y traten de desensamblar a mano el programa PEDEMO.EXE. Con solo un editor HEX, o si no se atreven, con el OllyDbg pero sin mirar las instrucciones. Si pueden hacer esto y además se divierten, definitivamente les va a gustar programar en Ensamblador.
Prog, Hex and Rock’n’Roll
–Todo Sobre el Sistema Hexadecimal–
Los sistemas numéricos son un mal necesario en el mundo de la computación, de hecho, el sistema decimal es sencillo de manejar y es el que mejor conocemos, pero para la computadora no significa nada. El binario es su idioma nativo y es con el que trabaja. Pero es demasiado tardado y confuso usarlo. La pregunta de los 65,536 sería ¿Habrá un sistema numérico que tenga las ventajas de ambos? La respuesta es si, se llama sistema hexadecimal y será el tema de esta nota.
Antes de continuar, se que este blog tiene 2 tipos principales de lectores (sin contar a los que vienen por la botana y a ligar) la primera clase son los lamercitos de escuela que les dejan de tarea copiar e imprimir páginas de internet como esta y la otra, los menos, son los principiantes que realmente les interesa el Ensamblador. En realidad, sería raro que un programador de cierto nivel buscara información en español. Mas bien teclean “Assembly Language” en el Google. Así que tomaré esto con calma.
Los ‘números’ de todos los días son 10, y van del 0 al 9. Los hexadecimales son 16. Se usan las letras de la A a la F para representar del 10 al 15. Vean la siguiente tabla:
DECIMAL HEXADECIMAL BINARIO
0 0 0000
1 1 0001
2 2 0010
3 3 0011
4 4 0100
5 5 0101
6 6 0110
7 7 0111
8 8 1000
9 9 1001
10 A 1010
11 B 1011
12 C 1100
13 D 1101
14 E 1110
15 F 1111
Esta tabla es importante, así que les recomiendo que la impriman y la peguen en la pared junto al programa PEDEMO.EXE del Fasm. Ahora veamos como hacer las conversiones rápidas.
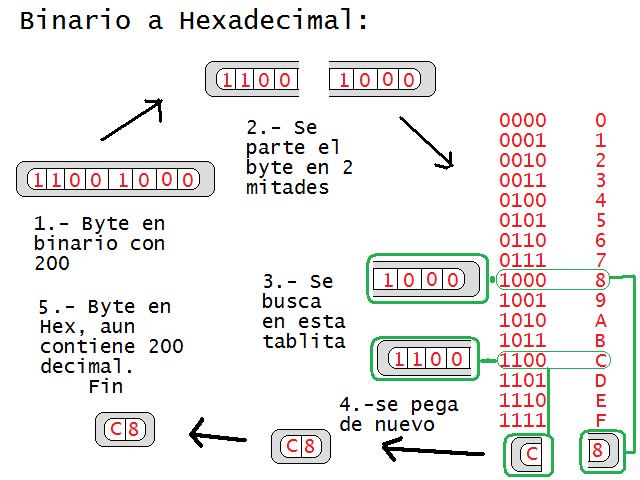
El primer paso para convertir un número a sistema Hexadecimal es convertirlo a binario. Moverse entre decimal y hexadecimal es mentalmente muy tardado y requiere mucha experiencia. Para el caso de las celdas de un BYTE, primero hay que escribir los 8 bits. Esa ristra de ceros y unos se parte en 2 mitades de 4 bits cada una y a continuación se convierte cada una de estas viboritas(llamadas NIBBLES en los libros mas antiguos) equivale exactamente a una cifra Hexadecimal. El dibujo que acompaña a esta entrada describe de manera clara como se convierte una celda de 8 bits a hexadecimal. Pero antes de que se harten y se vayan a trabajar en Visual Basic (las palabras ‘programar y ‘Visual Basic’ no pueden ir en la misma frase) veamos algunas de las virtudes de los números hexadecimales:
*La conversión entre Hexadecimal y Binario se puede hacer mentalmente de manera muy rápida.
*Con solo ver un número hexadecimal podemos saber cuantos bits se necesitan para representarlo.
*Podemos saber si un entero es positivo o negativo con solo ver su primer cifra hexadecimal.
*En cuanto a las posiciones de memoria. Podemos saber si están alineadas adecuadamente por la cantidad de ceros al final.
*No importa que número representemos, mientras solo usemos 2 cifras no sobrepasaremos el límite de un byte. Lo mismo aplica para las 4 cifras en un word(l6 bits) y 8 cifras para el DWORD (32 bits)
*El máximo número representable por un byte es ‘FF’, de un word es ‘FFFF’ y de un dword es ‘FFFFFFFF’. En el caso de la aritmética entera, estos números también significan menos uno.
*Si no aprenden Hexadecimal van a cagar chayotes cuando quieran programar de verdad. Así que pónganse a practicar o si no vayan buscándose algún trabajo mas sencillo como hacer querys.
Existe otro sistema llamado Octal, que es lo mismo pero cada cifra es representada por 3 bits. No se usa mucho, solo lo he visto para representar OpCodes en Intel y algunas cosas con los discos duros. Y si ya se aburrieron esperen a ver lo que sigue, será una auténtica ‘bienvenida al Mundo Real’.
>>>>Pasa al siguiente nivel>>>>
***Esta nota pertenece a “La Saga del Completo Principiante”*** Da click en este enlace para pasar a la siguiente entrada de esta serie.
Piensa en un Número
–Fundamentos del Sistema Binario–
Existe un juego de niños que supuestamente es para averiguar el número que alguien está pensando, no recuerdo los detalles técnicos pero mas o menos consiste en ver una serie de cartas con cifras impresas y decir si la que uno tiene en mente aparece o no en cada una. Al final el que muestra las cartas dice en voz alta la cifra oculta y todos aplauden. El sistema de este juego consiste en la numeración binaria. Esta entrada es sobre una manera sencilla de conviertir un número ‘normal’ al hermético sistema binario.
Antes de entrar en los detalles escabrosos, debo denunciar que en la carrera de ingeniería en computación de casi todas las universidades (con ‘u’ minúscula) se enseña un método que consiste en dividir el número normal entre dos y anotar el residuo, volver a dividir el cociente entre dos y anotar de nuevo el residuo y así hasta que el resultado de la división sea cero, para después voltearse y ya escribirse en binario. Este método es bueno para convertir un número ‘normal’ a otro de cualquier base, (solo hay que cambiar el divisor por la base que queramos) pero en mi opinión dicho método es demasiado tardado y complicado, no nos da información sobre desbordamientos, signos y es muy fácil equivocarse en el valor posicional.
Otra razón es que los ‘números normales’ son el patito feo en el mundo de las computadoras. Los sistemas verdaderamente importantes son el binario, el octal y el hexadecimal. Convertir números entre estos 3 sistemas es extraordinariamente sencillo y lo veremos cuando acaben de leer esta entrada. Y es mas sencillo convertir de decimal a binario que a octal o hexadecimal. El método que usaremos hoy (que no lo inventé pero es el que me funciona ) se basa en 9 pasos
1.- Si el número es mayor que 255 no puede representarse con un byte y nos vamos al demonio.
2.- Si al número le podemos restar 128, le restamos y escribimos un uno, si no se puede escribimos un cero
3.-Vemos si al resultado anterior le podemos restar 64, si es así le restamos 64 y escribimos un uno, si no se puede escribimos un cero.
4.-Vemos si al resultado anterior le podemos restar 32, si es así le restamos 32 y escribimos un uno, si no se puede escribimos un cero.
5.-Vemos si al resultado anterior le podemos restar 16, si es así le restamos 16 y escribimos un uno, si no se puede escribimos un cero.
6.-Vemos si al resultado anterior le podemos restar 8, si es así le restamos 8 y escribimos un uno, si no se puede escribimos un cero.
7.-Vemos si al resultado anterior le podemos restar 4, si es así le restamos 4 y escribimos un uno, si no se puede escribimos un cero.
8.-Vemos si al resultado anterior le podemos restar 2, si es así le restamos 2 y escribimos un uno, si no se puede escribimos un cero.
9.-Vemos si al resultado anterior le podemos restar 1, si es así le restamos 1 y escribimos un uno, si no se puede escribimos un cero.
Este es el método que conozco, restas sucesivas sobre el número a convertir, si si puede restar se escribe uno y se resta, si no se puede (o el resultado de restar es negativo) se escribe un cero. Este método escribe exactamente 8 cifras, que es el ancho de una celda de byte. Por ejemplo, el 255 arroja ocho unos, el cero una cadena de 8 ceros, etc. Para cantidades mayores a 255 se usan celdas de byte combinadas. Por ejemplo, con 2 celdas de byte tenemor 16 bits y podemos representar desde el 0 hasta el 65535, con 4 celdas tenemos 32 bits y podemos representar desde 0 hasta el 4,294,967,296. Este numerote es importante, pues la mayor parte de los datos en una PC con Windows usan enteros de 32 bits. Bueno, una nota mas en este blog. Espero que este método les sirva sobre todo a los estudiantes de primer semestre de ingeniería en computación, al menos antes de que muten en un DBA de 150 kilos. Pues si lo hacen nunca van a necesitar usar números binarios, estos solo son para los programadores de Ensamblador y uno que otro programador despistado de c.
>>>>Pasa al siguiente nivel>>>>
***Esta nota pertenece a “La Saga del Completo Principiante”*** Da click en este enlace para pasar a la siguiente entrada de esta serie.
Lenguaje Ensamblador:

–¡El mas dificil de dominar de todos los lenguajes de programación en la historia de las computadoras! ¿Serás tú uno de los pocos privilegiados capaces de lograrlo?–
Comentarios recientes
asm86 en Operación Tridente Cristian Figueroa en Operación Tridente Manuel en Destierro de 32 Bits Daniel Hung en ¿Alguien vio TRON? Protoss en Juegos en ensamblador
Click Para Contactarme

 Programacion en Lenguaje Ensamblador
Programacion en Lenguaje Ensamblador- Operación Tridente
- La Campaña del Pulpo
- Las Cuevas de 64 Bits
- Modo Protegido 021: Un MacGuffin para llevar
- Modo Protegido 020: Hola de Nuevo, Linux
- Modo Protegido 019: Crunch Time
- Modo Protegido 018: El Fracaso de Square-Enix Latinoamérica
- Modo Protegido 017: Sound Test
- Modo Protegido 016: Como programar un clon de Star Raiders
- Modo Protegido 015: El Caso Yogome y La Industria de Videojuegos de México
